kojacek
-
Postów
287 -
Dołączył
-
Ostatnia wizyta
-
Wygrane w rankingu
45
Treść opublikowana przez kojacek
-

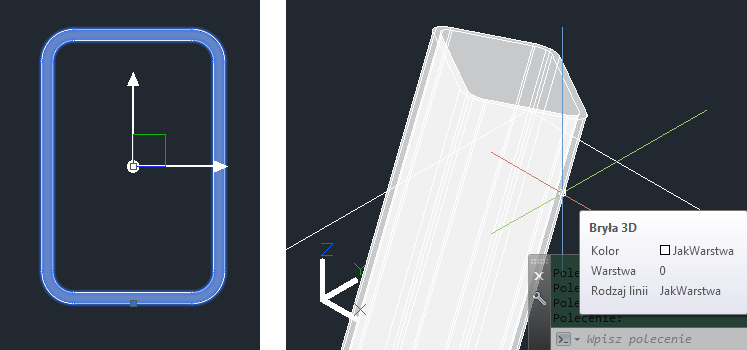
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Nie o LUW, z LUW-em nie ma problemu - tu się wstawi zabezpieczenie że ma być w globalnym i jest po krzyku. Chodzi o nazwy bloków zawierające podkreślnik lub spację. Aby można było wybrać blok z "wolnej ręki", lista bloków przekazywana jest do initget. To zaś powoduje że nazwy są "rozrywane" (podkreślnik służy do lokalizowania nazw, spacej to separatory). Są dwa rozwiązania: 1) Rezygnacja z wpisywania ręcznego (jest wybierz, i wybór z listy, oraz enter jako ostatni) 2) Dodanie słowa kluczowego do wpisu czyli zgłoszenie typu: Profil [Lista/Wybierz/Nazwa]<IPE500>: czyli Lista - wiadomo, Wybierz - wiadomo, i trzeba dodatkowo Nazwa, aby podać nazwę bloku (tu już bez initgeta, tylko zakres listy), enter - wiadomo To jest dodatkowe wydłużenie operacji -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Niestety jest jeden dość duży błąd, ujawniający się w pewnych okolicznościach. Póki co pracuję nad tym... :( -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Kolejny etap do testowania... Jeśli chodzi powinien: 1) Rozpoznawać prawidłowe bloki 2) "Urozmaicić wybór", poprzez: podanie nazwy z ręki / wybranie z listy / wskazanie bloku 3) Zapamiętywać ostatnie ustawienia 4) No i polecenie ma skrócone - teraz jest B3D Kod: ; =========================================================================================== ; (load "CADPL-Pack-v1.lsp" -1) ; =========================================================================================== ; (defun C:B3D ()(ExtrIns)(princ)) ; =========================================================================================== ; (defun ExtrIns (/ LBlk InsName StartP EndP PathEnt InsObj) (if (not (setq LBlk (BlockProfileList))) (princ "\nW rysunku nie zdefiniowano bloków dla profili. ") (progn (if (not *B3D-Settings*)(setq *B3D-Settings* (list (car LBlk) 1.0))) (if (setq StartP (getpoint "\nPierwszy punkt linii definiującej ścieżkę: ")) (if (setq EndP (getpoint StartP "\nKoniec ścieżki: ")) (if (setq InsName (GetBlockProfileName LBlk)) (progn (cd:SYS_UndoBegin) (setq InsObj (cd:BLK_InsertBlock StartP InsName '(1 1 1) 0 T)) (SetInsertZOrient (NewVect StartP EndP) (setq InsObj (vlax-vla-object->ename InsObj)) ) (setq PathEnt (cd:ENT_MakeLine (getvar "CTAB") StartP EndP T)) (ExtrudeProfile (vlax-ename->vla-object InsObj) PathEnt) (cd:SYS_UndoEnd) ) ) ) ) ) ) ) ; =========================================================================================== ; (defun GetBlockProfileName (LProf / f k s) (setq f (car *B3D-Settings*) s (car (mapcar '(lambda (%)(cd:STR_ReParse LProf %))(list " "))) ) (initget (strcat "Lista Wybierz " s)) (setq k (vl-catch-all-apply 'getkword (list (strcat "\nProfil [Lista/Wybierz] lub podaj nazwę <" f ">: ")) ) ) (if (not k) f (if (= (type k) 'STR) (cond ( (= k "Lista")(ProfileDlg LProf)) ( (= k "Wybierz")(SelectBlock LProf)) (t k) ) ) ) ) ; =========================================================================================== ; (defun ProfileDlg (BlkL / r p) (setq r (cd:DCL_StdListDialog BlkL (vl-position (car *B3D-Settings*) BlkL) "Profile" "Wybierz:" 25 12 2 12 (list "&Ok" "&Anuluj") nil T T nil) ) (if r (progn (setq p (nth r BlkL)) (setq *B3D-Settings* (list p (cadr *B3D-Settings*)))) ) p ) ; =========================================================================================== ; (defun SelectBlock (Lst / e d s) (if (and (setq e (entsel "\nWybierz blok: ")) (setq d (entget (car e))) (= "INSERT" (cdr (assoc 0 d))) (member (strcase (setq s (cdr (assoc 2 d)))) (mapcar 'strcase Lst) ) ) (progn (setq *B3D-Settings* (list s (cadr *B3D-Settings*))) s ) ) ) ; =========================================================================================== ; (defun ExtrudeProfile (Blk Lin / Prf Crv Reg Del) (vla-explode Blk) (setq Prf (entlast)) (vla-delete Blk) (if (cond ( (= "LWPOLYLINE" (cdr (assoc 0 (entget Prf)))) (setq Crv (vlax-make-safearray vlax-vbObject '(0 . 0))) (vlax-safearray-put-element Crv 0 (vlax-ename->vla-object Prf)) (setq Reg (vla-AddRegion (cd:ACX_ASpace) Crv)) ) ( (= "REGION" (cdr (assoc 0 (entget Prf)))) (setq Reg (vlax-ename->vla-object Prf)) ) (t nil) ) (progn (vla-AddExtrudedSolidAlongPath (cd:ACX_ASpace) (if (= (type Reg )'VLA-OBJECT) Reg (setq Del (vlax-safearray-get-element (vlax-variant-value Reg) 0)) ) (vlax-ename->vla-object Lin) ) (if Del (vla-delete Del)) (foreach % (list Lin Prf)(entdel %)) ) ) ) ; =========================================================================================== ; (defun NewVect (p1 p2 / dt sq sm um uv) (setq dt (mapcar '- p2 p1) sq (mapcar '* dt dt) sm (apply '+ sq) um (sqrt sm) uv (mapcar '/ dt (list um um um)) ) ) ; =========================================================================================== ; (defun SetInsertZOrient (ExtrVec Ename / e b) (setq e (entget Ename) b (trans (cdr (assoc 10 e)) Ename ExtrVec) e (subst (cons 10 b)(assoc 10 e) e) e (subst (cons 50 0.0)(assoc 50 e) e) e (subst (cons 210 ExtrVec)(assoc 210 e) e) ) (entmod e) ) ; =========================================================================================== ; (defun BlockProfile-p (Name / l d) (if (= 1 (length (setq l (cd:BLK_GetEntity Name nil)))) (progn (setq d (entget (car l))) (or (and (= (cdr (assoc 0 d)) "LWPOLYLINE") (= 1 (logand 1 (cdr (assoc 70 d)))) ) (= (cdr (assoc 0 d)) "REGION") ) ) ) ) ; =========================================================================================== ; (defun BlockProfileList (/ l) (if (setq l (cd:SYS_CollList "BLOCK" (+ 1 2 4 8))) (acad_strlsort (vl-remove-if-not '(lambda (%)(BlockProfile-p %)) l)) ) ) ; =========================================================================================== ; (princ "\nZaładowano polecenie: B3D ") (princ) -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Wg moich testów - dwie listy: bloków wszystkich i dobrych czyli tych które akceptujemy (polilinia zamknięta lub region). Jak widać B2 jest skutecznie odfiltrowany: Przecież nie jest zabronione wykorzystanie LISP-a z funkcją (autoreklama): jk:LWP_CorrectStartEndPoint pokazaną na (autoreklama) https://kojacek.wordpress.com/polilinia-zamknieta/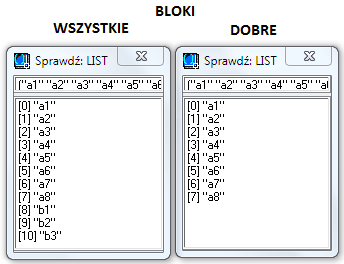
-
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Ale samo zamknięcie to połowa sukcesu. W tym przypadku "niehigieniczne" jest przecież także pokrywanie się pierwszego i ostatniego wierzchołka. Jeśli dobrze pamiętam regiony w AutoCAD-zie były dostępne chyba już w wersji 12 (z AME) czyli w ~ 1992 roku! :) -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Halo, halo panie Martin_S... Niechże mnie ktoś poprawi, ale czy nie jest tak że w blokach o nazwach IPE500 i IPE600, które gdzieś tutaj istnieją w przykładowych plikach, polilinie są OTWARTE, a nie (jak być powinno) zamknięte? Mylę się? O poliliniach otwartych a wyglądających jak zamknięte można przeczytać (autoreklama) tutaj: https://kojacek.wordpress.com/polilinia-zamknieta/ -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
A teraz moi mili, w następnym kroku niechże zrobi ktoś dwg-a, w którym niech sobie będzie z 5-10 bloków z profilami z LWPOLYLINE, kilka z REGION-ami, oraz kilka całkiem innych różnych bloczków. Po co? Otóż chcę przerobić wybieranie bloków na: 1) przez nazwę "z ręki" 2) przez nazwę z listy 3) przez wybór entycji (leży sobie gdzieś obok i się wskazuje) Całą "chytrość" wyboru chcę oprzeć na tym że sprawdzana jest zawartość bloku tak, aby np. liście (punkt 2) znalazło się tylko np. 10 bloków, (spełniających warunki) a pozostał (np. 20) - już nie. -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Hmm. W definicji bloku ma znajdować się jeden obiekt. Czyli w twoim przypadku nie dwa regiony a tylko jeden. Musi on być utworzony tak że w definicji bloku od większego regionu odejmujesz mniejszy. Wtedy jest jeden obiekt - definiowany przez (tutaj) dwa profile.
-
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Wprowadziłem na razie takie zmiany: 1) Rysowany jest profil bez użycia command. To jest wielokrotnie szybsze 2) Profil w bloku może być zamkniętą polilinią lub regionem. Oczywiście CADPack musi byc załadowany. Sprawdźcie czy to chodzi na ZW, bo nie miałem okazji próbować. Na Ac hula bez zarzutu. Oto kod: ; =========================================================================================== ; (defun C:EXTRINS (/ InsName StartP EndP PathEnt InsObj) (if (setq StartP (getpoint "\nPierwszy punkt linii definiującej ścieżkę: ")) (if (setq EndP (getpoint StartP "\nKoniec ścieżki: ")) (if (and (setq InsName (getstring "\nPodaj nazwe bloku: ")) (member (strcase InsName) (mapcar 'strcase (cd:SYS_CollList "BLOCK" (+ 1 2 4 8))) ) ) (progn (cd:SYS_UndoBegin) (setq InsObj (cd:BLK_InsertBlock StartP InsName '(1 1 1) 0 T)) (SetInsertZOrient (NewVect StartP EndP) (setq InsObj (vlax-vla-object->ename InsObj) ) ) (setq PathEnt (cd:ENT_MakeLine (getvar "CTAB") StartP EndP T)) (ExtrudeProfile (vlax-ename->vla-object InsObj) PathEnt) (cd:SYS_UndoEnd) ) ) ) ) (princ) ) ; =========================================================================================== ; (defun ExtrudeProfile (Blk Lin / Prf Crv Reg Del) (vla-explode Blk) (setq Prf (entlast)) (vla-delete Blk) (if (cond ( (= "LWPOLYLINE" (cdr (assoc 0 (entget Prf)))) (setq Crv (vlax-make-safearray vlax-vbObject '(0 . 0))) (vlax-safearray-put-element Crv 0 (vlax-ename->vla-object Prf)) (setq Reg (vla-AddRegion (cd:ACX_ASpace) Crv)) ) ( (= "REGION" (cdr (assoc 0 (entget Prf)))) (setq Reg (vlax-ename->vla-object Prf)) ) (t nil) ) (progn (vla-AddExtrudedSolidAlongPath (cd:ACX_ASpace) (if (= (type Reg )'VLA-OBJECT) Reg (setq Del (vlax-safearray-get-element (vlax-variant-value Reg) 0)) ) (vlax-ename->vla-object Lin) ) (if Del (vla-delete Del)) (foreach % (list Lin Prf)(entdel %)) ) ) ) ; =========================================================================================== ; (defun NewVect (p1 p2 / dt sq sm um uv) (setq dt (mapcar '- p2 p1) sq (mapcar '* dt dt) sm (apply '+ sq) um (sqrt sm) uv (mapcar '/ dt (list um um um)) ) ) ; =========================================================================================== ; (defun SetInsertZOrient (ExtrVec Ename / e b) (setq e (entget Ename) b (trans (cdr (assoc 10 e)) Ename ExtrVec) e (subst (cons 10 b)(assoc 10 e) e) e (subst (cons 50 0.0)(assoc 50 e) e) e (subst (cons 210 ExtrVec)(assoc 210 e) e) ) (entmod e) ) ; =========================================================================================== ; (princ) -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Co do bloków. Blokiem jest łatwiej operować: obrót, obrót 3d, skalowanie itp. Ma punkt bazowy, a definicja bloku determinuje kierunki, orientację itp. Ponadto ma nazwę, więc wybór profilu nie jest przypadkowy. Narysowana każdorazowo polilinia może nie spełniać zawsze wszystkich warunków. -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
A propos tych profili. Tak sobie myślę że jeśli jedziemy z bloków, to można się umówić że definicja takiego bloku może składać się zawsze i tylko z jednego obiektu będącym: 1) Zamkniętą LWPOLYLINE (tak jak tutaj jakieś tam IP które testowaliśmy) 2) Obiektu typu REGION - i tutaj możemy sobie pozwolić na bardziej wydumane kształty (np. rura, czy profil z otworami). Warunek - musi to być jeden obiekt I wtedy, można dopracować program tak, aby można było wybrać tylko taki rodzaj bloku (jeden obiekt jak powyżej) - reszta byłaby odrzucana. -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Przepraszam, jeśli można... Czy nie za szybko zamykamy? Powinno się to jeszcze poprawić: 1. Obsługa błędów. Wywalenie command. 2. Wybieranie bloków, skalowanie ewentualnie. 3. Sprawdzenie bloku (jeden profil) 4. Wprowadzenie innych zakończeń (trzy typy - jak tu Martin pokazywał) 5. (Opcjonalnie) te zabawy ze zmianą punktów (9 wstawień) -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Nie no, to dramat jakiś z tym zwcad... a pack teraz załadowany jest? -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Poprawiony kod (zamiast CD:SYS_UNDOSTART powinno być CD:SYS_UNDOBEGIN) Cały kod: ; =========================================================================================== ; (defun C:EXTRINS (/ InsName StartP EndP PathEnt InsObj Cmd) (if (setq StartP (getpoint "\nPierwszy punkt linii definiującej ścieżkę: ")) (if (setq EndP (getpoint StartP "\nKoniec ścieżki: ")) (if (and (setq InsName (getstring "\nPodaj nazwe bloku: ")) (member (strcase InsName) (mapcar 'strcase (cd:SYS_CollList "BLOCK" (+ 1 2 4 8))) ) ) (progn (cd:SYS_UndoBegin) (setq Cmd (getvar "CMDECHO")) (setq InsObj (cd:BLK_InsertBlock StartP InsName '(1 1 1) 0 T)) (SetInsertZOrient (NewVect StartP EndP) (setq InsObj (vlax-vla-object->ename InsObj) ) ) (setq PathEnt (cd:ENT_MakeLine (getvar "CTAB") StartP EndP T)) (vla-explode (vlax-ename->vla-object InsObj)) (entdel InsObj) (setvar "CMDECHO" 0) (command "_.EXTRUDE" (entlast) "" "_path" PathEnt) (setvar "CMDECHO" 1) (entdel PathEnt) (cd:SYS_UndoEnd) ) ) ) ) (princ) ) ; =========================================================================================== ; (defun NewVect (p1 p2 / dt sq sm um uv) (setq dt (mapcar '- p2 p1) sq (mapcar '* dt dt) sm (apply '+ sq) um (sqrt sm) uv (mapcar '/ dt (list um um um)) ) ) ; =========================================================================================== ; (defun SetInsertZOrient (ExtrVec Ename / e b) (setq e (entget Ename) b (trans (cdr (assoc 10 e)) Ename ExtrVec) e (subst (cons 10 b)(assoc 10 e) e) e (subst (cons 50 0.0)(assoc 50 e) e) e (subst (cons 210 ExtrVec)(assoc 210 e) e) ) (entmod e) ) ; =========================================================================================== ; (princ) -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Działa z blokiem teraz czy nie? A jeśli działa to jest źle czy dobrze? -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Spokojnie, póki co oczekuję informacji czy to co podałem działa, i czy działa w sposób, ogólnie oczekiwany. Nie da się zrobić wszystkiego na raz, zwłaszcza że zmienia się co chwilę zdanie (raz blok fajny, innym razem niefajny). -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Zrobiłem to na podstawie Twojego pliku DWG który tu opublikowałeś na początku. Tam jest jest blok IPE500, testowałem LISP-a na tym właśnie przykładzie. Blok jest o tyle dobry bo można go "porządnie" zdefiniować (właśnie zamknięcie polilinii), jak też określić dla całości orientację (gdzie "dół / góra) itp. -
Wyciągnięcie bryły pomiędzy dwoma punktami (po linii prostej).
kojacek odpowiedział(a) na Martin_S temat w Wsparcie programistyczne LISP i VisualLISP
Na sam początek. Od razu pewne uwagi: 1) Polecenie EXTRINS wyciąga profil (jedna polilinia w definicji bloku), po ścieżce będącej linią utworzoną przez wskazanie dwóch punktów. 2) To na razie robocza "brudna" wersja do testowania - bez obsługi błędów i z commandem (docelowo bez niego bym wolał) 3) Podczas pracy układ współrzędnych powinien być globalnym (nie ma potrzeby niczego zmieniać) 4) Na razie blok profilu trzeba podać ręcznie przez nazwę. W przyszłości można zastosować listę w oknie i (lub) przez wskazanie bloku. 4) Profil jest ustawiany "prostopadle" do linii wyciągnięcia. To podstawowa cecha. W przyszłości można będzie ustawić go "pod kątem" (generalnie na płaszczyźnie GUW raczej.) 5) Testujcie. Nie wiem czy to będzie chodzić na wszystkich waszych ZwCAD-ach, ale zobaczymy. 6) Ostatnia uwaga, trzeba załadować CADPL-Pack'a 7) Kod: ; =========================================================================================== ; (defun C:EXTRINS (/ InsName StartP EndP PathEnt InsObj Cmd) (if (setq StartP (getpoint "\nPierwszy punkt linii definiującej ścieżkę: ")) (if (setq EndP (getpoint StartP "\nKoniec ścieżki: ")) (if (and (setq InsName (getstring "\nPodaj nazwe bloku: ")) (member (strcase InsName) (mapcar 'strcase (cd:SYS_CollList "BLOCK" (+ 1 2 4 8))) ) ) (progn (cd:SYS_UndoStart) (setq Cmd (getvar "CMDECHO")) (setq InsObj (cd:BLK_InsertBlock StartP InsName '(1 1 1) 0 T)) (SetInsertZOrient (NewVect StartP EndP) (setq InsObj (vlax-vla-object->ename InsObj) ) ) (setq PathEnt (cd:ENT_MakeLine (getvar "CTAB") StartP EndP T)) (vla-explode (vlax-ename->vla-object InsObj)) (entdel InsObj) (setvar "CMDECHO" 0) (command "_.EXTRUDE" (entlast) "" "_path" PathEnt) (setvar "CMDECHO" 1) (entdel PathEnt) (cd:SYS_UndoEnd) ) ) ) ) (princ) ) ; =========================================================================================== ; (defun NewVect (p1 p2 / dt sq sm um uv) (setq dt (mapcar '- p2 p1) sq (mapcar '* dt dt) sm (apply '+ sq) um (sqrt sm) uv (mapcar '/ dt (list um um um)) ) ) ; =========================================================================================== ; (defun SetInsertZOrient (ExtrVec Ename / e b) (setq e (entget Ename) b (trans (cdr (assoc 10 e)) Ename ExtrVec) e (subst (cons 10 b)(assoc 10 e) e) e (subst (cons 50 0.0)(assoc 50 e) e) e (subst (cons 210 ExtrVec)(assoc 210 e) e) ) (entmod e) ) ; =========================================================================================== ; (princ) -
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
Funkcja z przedrostkiem C: to specjalna definicja funkcji lispowej - najoględniej mówiąc tworzy polecenie AutoCAD-a, zdefiniowane w LISP-ie. Wywołanie jej działa jak polecenie, można je wywołać z linii poleceń. Taka funkcja nie może mieć argumentów. Natomiast "zwykłe" funkcje można wywołać w linii poleceń, ale trzeba je wywoływać w pełnej składni wymaganej przez interpreter LISP-a, czyli w nawiasach i z argumentami (jeśli funkcja je posiada). I tak, namaluj coś i w linii poleceń napisz: (entlast) funkcja zwróci ename ostatniego obiektu. Teraz wywołaj funkcję z argumentem np. : (entget (entlast)) dostaniesz listę DXF danych tego obiektu. Tak samo wywołujesz funkcję SelRect: (SelRect) Drugi problem. Kierunek polilinii. Potrzebujesz funkcji napisanej przez gile'a. Wygląda tak: ;; Clockwise-p - Gilles Chanteau (gile) ;; Returns T if p1,p2,p3 are clockwise oriented (defun gc:clockwise-p (p1 p2 p3) (< (sin (- (angle p1 p3) (angle p1 p2))) -1e-14) ) Zwraca T jeśli 3 punkty podane jako argumenty funkcji tworzą kąt zorientowany zgodnie z ruchem wskazówek zegara, lub nil w przeciwnym wypadku. Potem można już zdefiniować polecenie sprawdzające polilinię. Musi ona mieć co najmniej dwa wierzchołki. Funkcja może wyglądać tak: (defun C:TESTCLP (/ e d p) (if (and (setq e (entsel "\nWybierz polilinie: ")) (= (cdr (assoc 0 (setq d (entget (car e))))) "LWPOLYLINE") ) (if (> (length (setq p (cd:DXF_massoc 10 d))) 2) (gc:clockwise-p (car p)(cadr p)(caddr p)) ) ) ) -
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
Tymczasem wróćmy (bośmy nieco "zboczyli"... ;) ) do wyboru polilinii. Krótko jeszcze o "zadaniu domowym". Spójrzmy na obrazek porównujący prostokąt z "kokardką": Pożądany przez nas czworokąt będący prostokątem można sprawdzić też w ten sposób: Weźmy dwa sąsiednie boki (np. 1-2 i 2-3). Wybierzmy najdłuższy z nich (tu będzie to 1-2). I teraz sprawdzamy: w prostokącie ten najdłuższy z boków musi być krótszy od długości przekątnej (np. 1-4), dodatkowo oczywiście to (przekątne) jednocześnie muszą być sobie równe. I to chyba w zupełności wystarczy? Kod "zadania domowego": (defun SelRect (/ e d rect-p) (defun rect-p (p / d) (if ; jezeli (not (zerop (distance (car p)(cadddr p)))) ; 1 i 4 pkt sie nie pokrywaja (and ; sprawdz (equal ; czy jest rowna (setq d (distance (car p)(caddr p))) ; dlugosc 1 przekatnej (distance (cadr p)(cadddr p)) ; i 2 przekatnej? 0.001 ) (< ; i najwiekszy (max ; bok z 1 i 2 (distance (car p)(cadr p)) ; jest (distance (cadr p)(caddr p)) ; mniejszy ) d ; od przekatnej ) ) ; T (spelnia warunki) ) ; nil (nie spelnia) ) (if (and (setq e (entsel "\nWskaż prostokąt: ")) ; jest wybor (= (cdr (assoc 0 (setq d (entget (car e))))) "LWPOLYLINE") ; to LWPoly (= 1 (logand 1 (cdr (assoc 70 d)))) ; jest zamknieta (zerop (apply '+ (mapcar 'abs (cd:DXF_massoc 42 d)))) ; nie ma seg. lukowych (= (cdr (assoc 90 d)) 4) ; ma 4 wierzcholki (rect-p (cd:DXF_massoc 10 d)) ; jest prostokatem ) (princ "\nOk") (princ "\nŹle. ") ) ) wzbogacony o komentarze, które pozwolą łatwiej prześledzić działanie.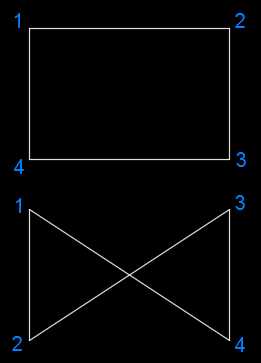
-
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
Chyba się nie rozumiemy do końca. W mojej opinii budowanie funkcji (a bibliotecznych szczególnie) ma na celu (między innymi) skracanie kodu. Przykłady które zaprezentowałeś idą w przeciwnym kierunku. "Moje" ośmiolinijkowe <and> (z jedną tylko funkcją lokalną) zastępujesz sześcioma funkcjami (już nie liczę ilości linii). Na koniec twierdzisz że jest to bardziej czytelne. Pozornie tak (są nazwy), w istocie śledzenie kodu jest jednak dużo trudniejsze. Zobacz. Przykładowa funkcja biblioteczna (stosunkowo krótka) może nas informować jednocześnie czy polilinia jest zamknięta, czy jest PLINEGEN i czy zawiera szegmenty łukowe: (defun GetPolyProp (Ent / d) (setq d (entget Ent)) (+ (cdr (assoc 70 d)) (if (zerop (apply '+ (mapcar 'abs (cd:DXF_massoc 42 d)))) 0 256) ) ) Wywołanie: (GetPolyProp (car (entsel))) Stosuję jedną funkcję (tylko jedno wywołanie), i mam jednocześnie trzy informacje. Takie podejście (skracanie kodu) uważam za lepsze jeśli chodzi o czytelność. Oczywiście, abyśmy się zrozumieli - w żadnym wypadku nie deprecjonuję innych rozwiązań. -
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
Zaraz strzelanie. Są co najmniej dwie drogi obejścia nieszczęśliwego ESC. Dlaczego o jednej i (tylko jednej) właśnie już teraz ma się dowiedzieć Iskra i każdy inny? Oczywiście może, ale (w mojej opinii) ważniejszym jest skoncentrowanie się na szerszym spojrzeniu na zagadnienie poprawnego wyboru obiektu. Określeniu warunków, i ich sprawdzeniu itp. Obsługa błędów, ogólnie rzecz biorąc jest zwykle "wisienką na torcie". Nadal nie jestem przekonany czy HasArcSegment jest czytelniejsze niźli (zerop (apply '+ (mapcar 'abs (cd:DXF_massoc 42 EntityList)))) biorąc pod uwagę, że mogę dodać komentarz właśnie: ; Ma sgementy łukowe? a działanie i tak (w obu przypadkach) trzeba prześledzić w ten sam sposób. Oczywiście to moje subiektywne zdanie. -
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
Pozwolę sobie wyrazić swoją opinię, w sprawie trzech powyższych punktów. Ad 1. Zgoda, ale chyba za wcześnie na to wszystko. Do tej pory odnosiłem wrażenie że wątek mając nieco charakter edukacyjny, powoli rośnie zwiększając poziom zaawansowania. Zwłaszcza że kolega Iskra (zakładając wątek) sam nadmienił że się dopiero uczy. Napisał kawałek dość dobrego kodu (w ogólności co do zasady), nie wystrzegł się paru błędów, ale nie zniechęcajmy go jednak na samym początku. Na vl-catch-all-apply przyjdzie jeszcze czas. Na razie bez radykalnego zawsze i absolutnie. Póki co proste rzeczy, pytania i odpowiedzi. Chce wiedzieć, pyta, ma potencjał, na wszystko przyjdzie czas. Popatrz (że znów wrócę do CAD-Pack'a), nie mówię że wszystko jest do d*py, weź no funkcję cd:USR_EntSelObj, daj se spokój bo ona jest git... Na marginesie, warto na nią też popatrzeć. Ad 2. Różnić się będę także co do rzekomej czytelności kodu. Wydaje mi się że przedstawiona propozycja zaciemnia a nie rozjaśnia. Ogólnie jestem zwolennikiem stosowania funkcji w funkcji (mającej charakter lokalny) w dwóch przypadkach. Po pierwsze: podfunkcja (tak ją nazwijmy umownie), wywoływana jest wielokrotnie, lub (po drugie), jest na tyle obszerna że zaciemnia właśnie kod główny. Ten drugi przypadek widać w zastosowaniu funkcji dia wewnątrz SelRect. Wszystkie inne wywołania w and, (typ obiektu, zamknięcie, bulge itp.) wydają się na tyle proste że nie widzę potrzeby definiowania ich jako osobne funkcje. Zwłaszcza jako funkcje lokalne (mające zasięg tylko wewnątrz innej jednej funkcji). Spójrzmy, przykład pierwszy z brzegu. Kod: (defun IsPolyline (Entity / ) (= (cdr (assoc 0 Entity)) "LWPOLYLINE") ) właściwie niczego nie wnosi (oprócz zwiększenia objętości), bowiem samo: (= (cdr (assoc 0 Entity)) "LWPOLYLINE") wydaje się być i tak czytelne. Ewentualnie można je opatrzyć komentarzem. Powtórzę raz jeszcze - zwłaszcza jako funkcja lokalna. Co innego gdyby to była funkcja biblioteczna (mogąca mieć wielokrotne zastosowanie w wielu miejscach). Jestem zagorzałym zwolennikiem tworzenia funkcji bibliotecznych. Jednak uważam, należy zachować tutaj pewien umiar i szukać możliwie uniwersalnego zastosowania. Bowiem (jeszcze na tym przykładzie), gdyby nawet twoja IsPolyline, była nawet funkcją biblioteczną, jej sens i tak jest mocno wątpliwy. Bowiem tym tropem trzeba by stworzyć tyle funkcji ile jest typów obiektów (Isline, IsArc, IsCircle... etc.) Nie trzeba wiele analizować że nie ma to sensu. W tym przypadku funkcja biblioteczna mogłaby być jedna i sprawdzać czy podany obiekt jest akceptowany wg jakiegoś kryterium (tutaj rodzaj obiektu). Na przykład definicja: (defun GetTypeObj (Ent TypeLst) (car (member (cdr (assoc 0 (entget Ent))) TypeLst)) ) i potem przykładowe wywołania: (GetTypeObj (car (entsel)) '("LWPOLYLINE" "LINE" "ARC")) pozwala określić ze wskazania czy to jest polilnia albo linia albo łuk czy: (GetTypeObj (car (entsel)) '("LWPOLYLINE")) zawęzić typ tylko do polilinii. Podsumowując - w mojej opinii - poprzez przerost definicji funkcji zaciemniłeś, a nie rozjaśniłeś kod. Ad 3. Powtórzę to co w Ad 1. Ogólnie zgoda, niemniej tutaj testujemy budowanie prostej funkcji ilustrując jej działanie, tak aby była zrozumiała, na tym poziomie ogólności. W tej chwili potrzebujemy informacji czy wybór jest ok czy be. Gdy to przejdziemy nastąpić może ciąg dalszy (coś się dzieje gdy jest ok, coś innego gdy jest be). -
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
No to zadanie domowe nam urosło... ;) Proponuję dodatkowo sprawdzenie (porównanie) pól polilini: Otrzymanych z pomnożenia długości 1 i drugiego boku, oraz właściwości Area obiektu. Zdaje się że każde "skrzywienie" geometrii (pomimo równych przekątnych) powinno dać różne wyniki. Zmodyfikowana SelRect wygląda tak: (defun SelRect (/ e d dia) (defun dia (l p) (if (not (zerop (distance (car p)(cadddr p)))) (and (equal (distance (car p)(caddr p)) (distance (cadr p)(cadddr p)) 0.001 ) (equal (* (distance (car p)(cadr p))(distance (cadr p)(caddr p))) (vla-get-Area (vlax-ename->vla-object l)) 0.001 ) ) ) ) (if (and (setq e (entsel "\nWskaż prostokąt: ")) (= (cdr (assoc 0 (setq d (entget (car e))))) "LWPOLYLINE") (= 1 (logand 1 (cdr (assoc 70 d)))) (zerop (apply '+ (mapcar 'abs (cd:DXF_massoc 42 d)))) (= (cdr (assoc 90 d)) 4) (dia (car e)(cd:DXF_massoc 10 d)) ) (princ "\nOk") (princ "\nŹle. ") ) ) -
Najmniejszy opisany prostokąt - LISP
kojacek odpowiedział(a) na Iskra temat w Wsparcie programistyczne LISP i VisualLISP
Zadanie domowe rozwiązane bardzo dobrze (choć bez funkcji), ale ok. Funkcja może wygladać tak: (defun SelRect (/ e d dia) (defun dia (p) (if (not (zerop (distance (car p)(cadddr p)))) (equal (distance (car p)(caddr p)) (distance (cadr p)(cadddr p)) 0.001 ) ) ) (if (and (setq e (entsel "\nWskaż prostokąt: ")) (= (cdr (assoc 0 (setq d (entget (car e))))) "LWPOLYLINE") (= 1 (logand 1 (cdr (assoc 70 d)))) (zerop (apply '+ (mapcar 'abs (cd:DXF_massoc 42 d)))) (= (cdr (assoc 90 d)) 4) (dia (cd:DXF_massoc 10 d)) ) (princ "\nOk") (princ "\nŹle. ") )) SelRect, ma w sobie zdefiniowaną funkcję dia, która zwraca T jeżeli z listy punktów wynika że odległości 1-3 i 2-4 (przekątne) są równe (z tolerancją .001). Trzeba zwrócić uwagę na sprawdzenie czy pierwszy i ostatni punkt się nie pokrywają - eliminuje to przypadek listy 4 współrzędnych definuijących w rzeczywistości trójkąt, a nie czworokąt. Funkcja jest argumentacyjna, i wstawiona jest jako kolejny element w and. Czyli wyszło teraz tak: - coś wybrane - to jest LWPoly - jest zamknięta - nie ma łuków - ma 4 wierzchołki - przekątne są równe... Wracając do naszej funkcji wyboru, można niektóre warunki zargumentyzować np. otwarta/zamknięta itp. W następnym odcinku możemy to spróbować. Masz rację! Trzeba dodać jeszcze jeden inny warunek. Jaki będzie najprościej?